Agent Harness 正在成为构建 Agent 的主流方式,而且它不会消失。 这些 harness 与 Agent 记忆紧密绑定。如果你使用了一个封闭的 harness——尤其是那种封装在私有 API 背后的——你实际上是把 Agent 记忆的控制权交给了第三方。记忆对于创造优质且持久的 Agent 体验至关重要。这会带来巨大的锁定效应。记忆——从而也包括 harness——应该是开放的,让你真正拥有自己的记忆。
Agent Harnesses:构建 Agent 的方式,不会消失
过去三年,构建 Agentic 系统"最佳方法"经历了剧烈变化。ChatGPT 出来后,你只能做简单的 RAG 链(LangChain)。后来模型变强了一点,能处理更复杂的流程(LangGraph)。再后来模型变得非常强大,催生了一种新型的脚手架——Agent Harness。
Agent Harness 的例子包括:Claude Code、Deep Agents、Pi(驱动 OpenClaw)、OpenCode、Codex、Letta Code 等等。
💡 Agent Harnesses 不会消失。
有一种观点认为,模型会逐渐吸收越来越多的脚手架功能。这是错误的。 实际情况是:2023 年需要的大量脚手架现在已经不需要了,但取而代之的是其他类型的脚手架。Agent,本质上就是 LLM 与工具及其他数据源的交互。围绕 LLM 的系统始终存在,用以协调这类交互。需要证据?Claude Code 源码泄露时,有 51.2 万行代码。那些代码就是 harness。连世界上最好的模型的开发者,都在大力投入 harness。
当 OpenAI 和 Anthropic 的 API 内置了网络搜索等功能时——那些并不是"模型的一部分",而是藏在 API 背后的轻量级 harness,通过工具调用(tool calling)来协调模型与网络搜索 API 的交互。
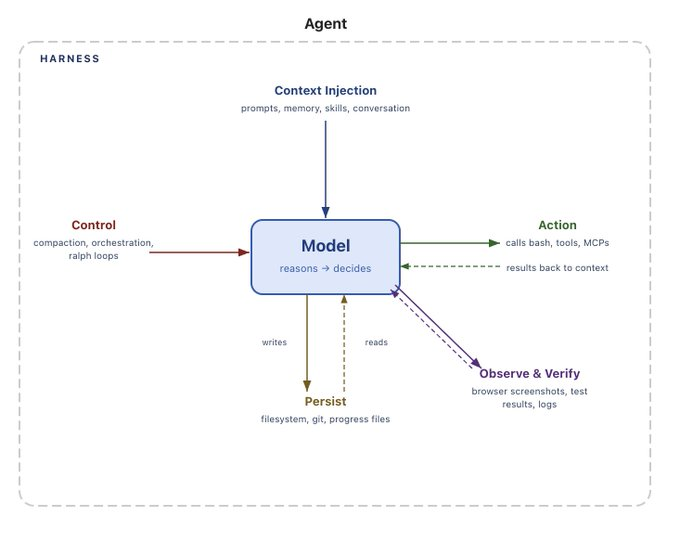
Harness 与记忆紧密绑定
Sarah Wooders 写了一篇很棒的文章《为什么记忆不是一个插件(它是 harness)》,我完全赞同。
有一种观点认为,记忆是一个独立的服务,独立于任何特定的 harness。在当前这个时间点,事实并非如此。
Harness 的一个重大职责是管理上下文交互。正如 Sarah 所说:
把记忆插入 Agent harness,就跟说"把驾驶能力插入汽车"一样荒谬。管理上下文,从而管理记忆,是 Agent harness 的核心能力和职责。
记忆只是一种上下文形式。 短期记忆(对话中的消息、大型工具调用结果)由 harness 处理。长期记忆(跨会话记忆)需要由 harness 更新和读取。Sarah 列出了 harness 与记忆绑定的多种方式:
AGENTS.md或CLAUDE.md文件是如何加载到上下文的?- 技能元数据是如何展示给 Agent 的?(在系统提示词里?系统消息里?)
- Agent 能修改自己的系统指令吗?
- 压缩(compaction)后什么保留了什么丢失了?
- 交互记录是否被存储并可查询?
- 记忆元数据是如何呈现给 Agent 的?
- 当前工作目录是如何表示的?暴露了多少文件系统信息?
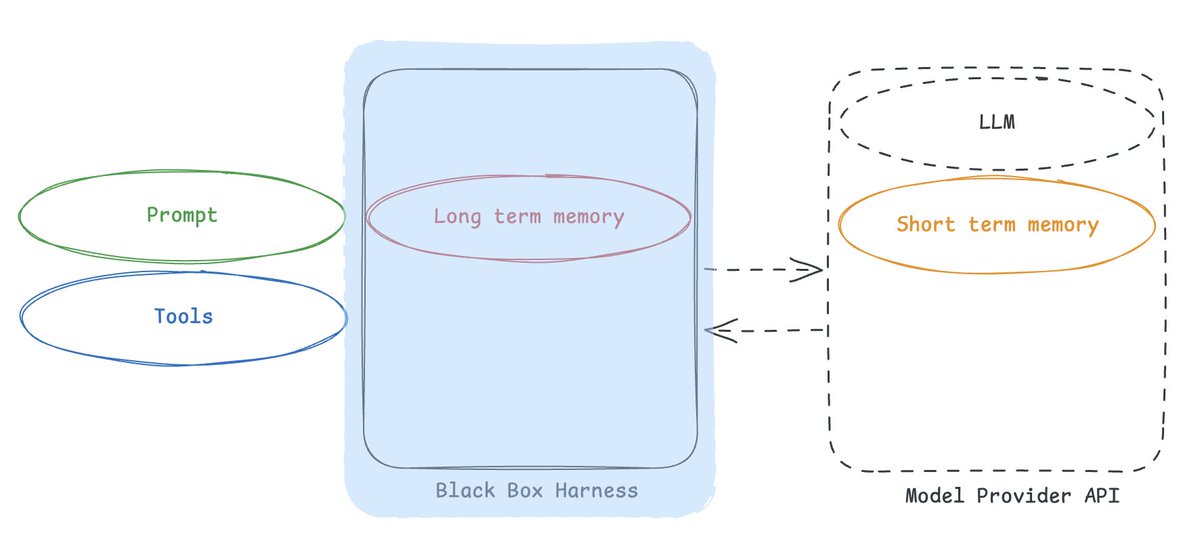
目前,记忆作为一个概念仍处于萌芽期。坦率地说,我们看到长期记忆往往不是 MVP 的一部分。首先你得让一个 Agent 正常运作,然后才考虑个性化。这意味着我们(作为整个行业)仍在摸索记忆。目前,记忆领域还没有知名或通用的抽象方案。如果未来记忆变得更成熟,我们找到了最佳实践,那么独立的记忆系统可能会开始变得合理。但那是以后的事。现在,正如 Sarah 所说:“归根结底,harness 如何管理上下文和状态,是 Agent 记忆的基石。”
如果你不拥有你的 Harness,你就不拥有你的记忆
Harness 与记忆紧密绑定。
💡 如果你使用了封闭的 harness,尤其是封装在 API 背后的,你就不是真正拥有自己的记忆。
这在几个层面上体现出来:
轻度糟糕: 如果你使用有状态的 API(如 OpenAI 的 Responses API,或 Anthropic 的服务端压缩),你的状态存储在他们的服务器上。如果你想切换模型并恢复之前的线程——那是做不到的。
糟糕: 如果你使用封闭的 harness(如 Claude Agent SDK,它底层使用 Claude Code,而 Claude Code 不是开源的),这个 harness 与记忆的交互方式对你来说是未知的。也许它在客户端创建了一些产物(artifact)——但这些产物的结构是什么?其他 harness 应该如何使用它们?这些都是未知的,因此无法从一个 harness 转移到另一个。
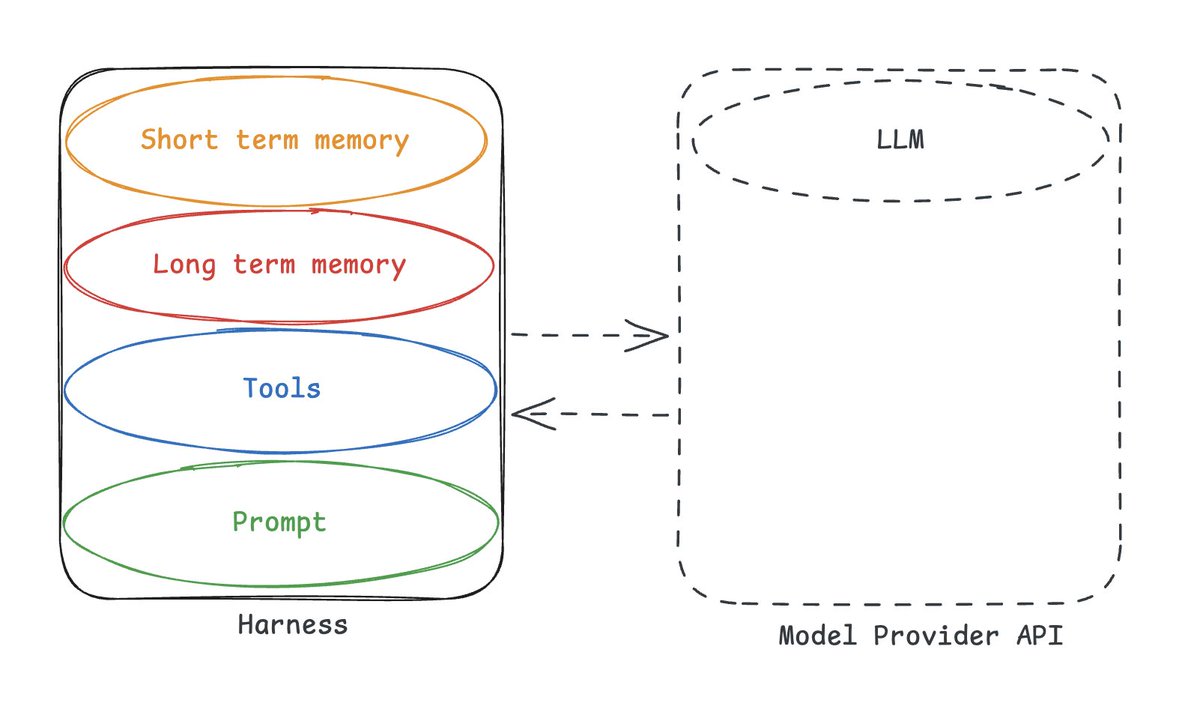
💡 但最糟糕的是——当整个 harness,包括长期记忆,都被封装在 API 背后。
这种情况下,你对记忆(尤其是长期记忆)没有任何所有权或可见性。你不了解 harness(这意味着你不知道怎么使用记忆)。但更糟糕的是——你甚至不拥有那些记忆! 也许部分通过 API 暴露了,也许完全没有——你对此毫无控制权。
当人们说"模型会吸收越来越多的 harness"时——他们真正意思是:这些与记忆相关的部分,将被锁定在模型提供商提供的 API 背后。
💡 这非常令人警觉——这意味着记忆将被锁定在单一平台、单一模型上。
模型提供商有巨大的动机这么做。而且他们已经开始这么做了。Anthropic 推出了 Claude Managed Agents,把所有东西都封装在 API 里,锁定在他们的平台上。
即使整个 harness 没有完全放到 API 背后,模型提供商也有动机把越来越多的东西移进 API——而且他们已经在做了。例如:Codex 虽然是开源的,但它生成了加密的压缩摘要(这在 OpenAI 生态系统之外是无法使用的)。
为什么他们这么做?因为记忆很重要,它创造了模型本身无法提供的锁定效应。
记忆很重要,它创造了锁定效应
虽然记忆尚在早期,但所有人都清楚它很重要。它让 Agent 能够随着用户交互而不断改进,让你构建起数据飞轮。它让你的 Agent 能够个性化服务每个用户,构建出符合其需求和使用模式的 Agent 体验。
💡 没有记忆,你的 Agent 很容易被任何能访问相同工具的人复制。
有了记忆,你就积累起专有的数据集——用户交互和偏好的数据集。这个专有数据集让你能提供差异化且日益智能的体验。
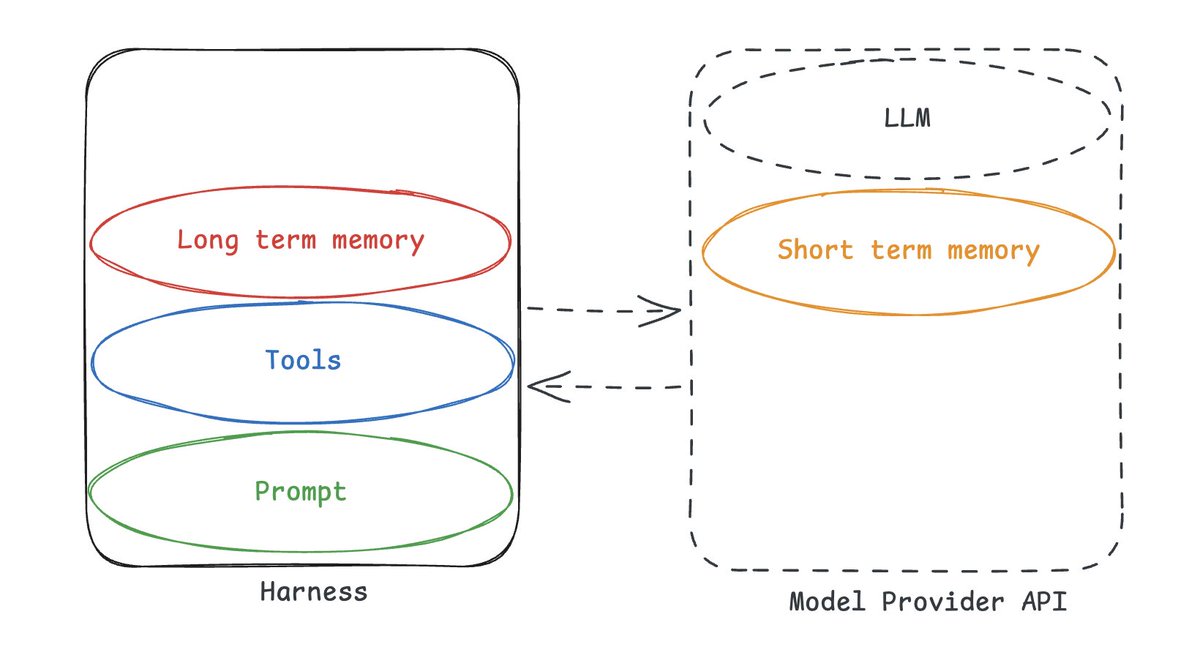
迄今为止,切换模型提供商相对容易。它们的 API 相似,甚至相同。当然,你得稍微改改提示词,但也不算难。
但这都是因为它们是无状态的。
一旦有任何关联的状态,切换就变得困难得多。因为这些记忆很重要。如果你切换了,你就失去了对它的访问。
我可以讲个故事。我内部有一个邮件助手。它构建在 Fleet(我们的无代码平台,用于构建企业级 OpenClaw)的一个模板上。这个平台内置了记忆功能,所以过去几个月我和我的邮件助手交互时,它积累了大量记忆。几周前,我的 Agent 不小心被删了。我非常恼火!我试图从同一个模板重建一个 Agent——但体验差了很多。我得重新教它我所有的偏好、我的语气、所有一切。
删掉我的邮件 Agent 的好处是——让我意识到记忆可以有多强大、多持久。
开放记忆,开放 Harnesses
记忆需要被开放出来,由开发 Agent 体验的人拥有。它让你能构建起你真正控制专有数据集。
记忆(从而也包括 harnesses)应该与模型提供商分离。 你应该保有选择权,可以尝试任何对你的用例最好的模型。模型提供商有动机通过记忆来创造锁定效应。
这就是为什么我们在构建 Deep Agents。Deep Agents:
- ✅ 开源
- ✅ 模型无关(model agnostic)
- ✅ 使用
agents.md和 skills 等开放标准 - ✅ 支持 MongoDB、Postgres、Redis 等插件来存储记忆
- ✅ 可部署:通过 LangSmith Deployment(可自托管、可部署在任何云上、可使用自己的数据库作为记忆存储);或部署在任何标准 Web 托管框架背后
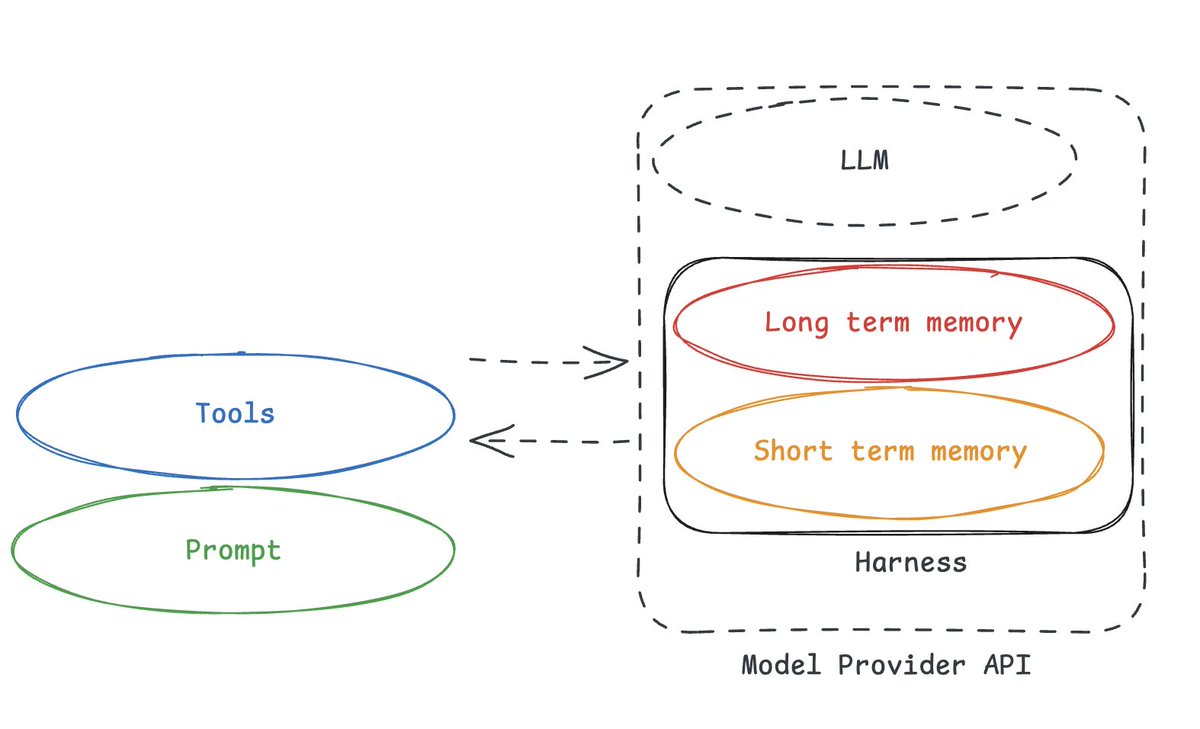
要拥有自己的记忆,你需要在使用一个开放的 Harness
今天就试试 Deep Agents 吧。
感谢以下朋友的审阅和建议:Sydney Runkle(Deep Agents 和记忆方向的大量工作)、Viv Trivedy(Agent Harness 领域的领先声音)、Nuno Campos(金融 Agent 上下文工程的优秀作者)、Sarah Wooders(Letta CTO,一家公司持续走在有状态 Agent 前沿)。
原文:Your harness, your memory | 作者:Harrison Chase(LangChain CEO)